
|
Muhammad WaseemClick on the email to unscramble.Academic Email: Personal Email: | Blog | |
|
I am a first-year MSc student in Computer Vision at MBZUAI, with a strong interest in building AI systems that are robust, fair, and trustworthy. Currently, I am working on enabling agent-based systems to self-learn from past failures, particularly in the context of jailbreaking and prompt-injection attacks, under the supervision of Nils Lukas. Previously, I worked on understanding and enhancing the capabilities of vision-language models for language-controlled document editing under Sanket Biswas and Josep Llados at Computer Vision Center. I was also briefly a visiting researcher under Dr. Karthik Nandakumar in the Sprint AI Lab, where I worked on federated learning for improving convergence in extreme non-iid scenarios using client contributions. You can also find me on other spaces below. ~ 𝕏 (Twitter) | Github | LinkedIn ~ |
|
Aug '25 |
Joined MBZUAI for MSc in Computer Vision with full ride scholarship. |
|
Dec '24 |
Our paper DocEdit Redefined: In-Context Learning for Multimodal Document Editing got accepted at WACV 2025 workshop 🥳! |
|
Sep '24 |
Ranked 45th out of thousand teams participated in Amazon ML Challenge 2024. Eligible for PPI for the role of Applied Scientist Intern. |
|
Jun '24 |
Our paper LineTR: Re-Imagining Text-Line Segmentation got accepted at ICPR 2024 🥳! |
|
Mar '24 |
Selected for UGRIP at MBZUAI with an acceptance rate of 4%. |
|
Dec '23 |
Selected as Research intern to work in Computer Vision Center, Spain. |
|
Nov '23 |
Awarded Merit Scholarship for academic excellence in the year 2022-2023. |
|
Feb '23 |
Selected for Summer Research internship at CVIT Lab in IIIT Hyderabad. |
|
Jan '23 |
Special mention award at NIT Trichy & DataNetiix hackathon for our Research digest prototype. |
|
Dec '22 |
Awarded Merit Scholarship for academic excellence in the year 2021-2022. |
|
Nov '22 |
Selected as the Student Coordinator for University's Annual Tech fest. |
|
Sept '21 |
Joined Shiv Nadar University Chennai for B.Tech in Artificial Intelligence and Data Science |
|
|
August '25 - May '27' GPA: 3.85 Supervisor: Nils Lukas |
|
|
September '21 - May '25 GPA: 9.67, Rank: 2 Student Societies:
|
|
|
July '24 - August '24 Working in SPriNT-AI (Security, Privacy and Trustworthiness in Artificial Intelligence) lab, focussing on effective utilization of shapley values in federated learning for non-iid setting. |
|
|
May '24 - June '24 Our project, conducted under Dr. Zhiqiang Shen (Jason), focused on "Optimizing Prompts for Foundation Models" to reduce hallucination. We curated a benchmark dataset of 25k questions across ~60 topics like law, philosophy, and history. Additionally, we developed a web application to collect human preferences and assess the correctness of responses before and after applying 26 guiding principles. This preference data is crucial for future preference-based optimization techniques, enhancing the accuracy and reliability of AI-generated responses |
|
|
Feb '24 - Aug '24 Worked on document editing, analyzing the potential of LLMs to generate structured commands to edit documents. This work resulted in a publication at WACV 2025 workshop. |
|
|
May '23 - Feb '24 Co-Developed on a novel method to achieve precise text line segmentation for complex Indic and Southeast Asian historical palm leaves. |
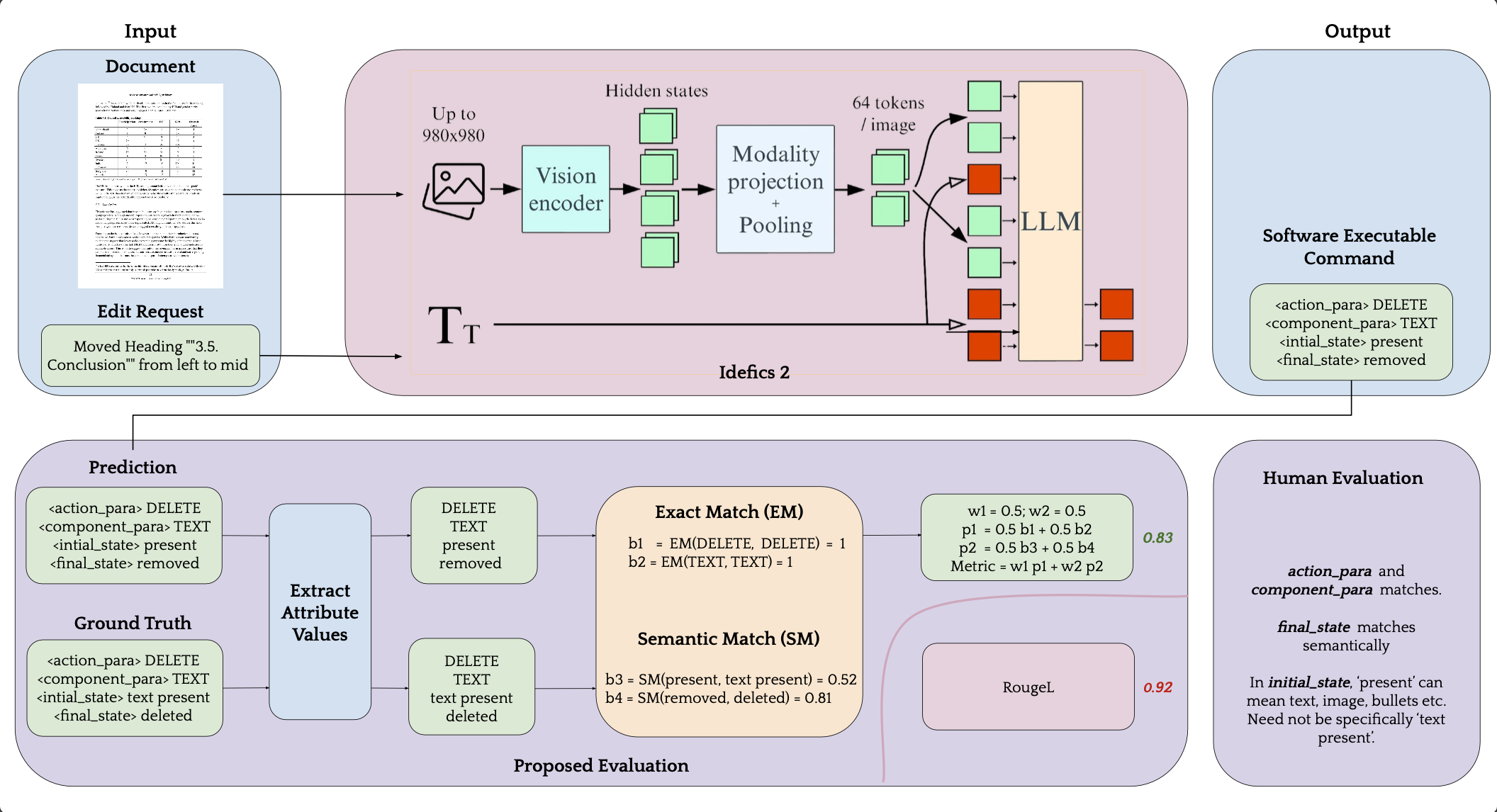
|
Muhammad Waseem, Sanket Biswas, Josep Llados
We introduce an innovative approach to structured document editing that uses Visual-Language Models (VLMs) to simplify the process by removing the need for specialized segmentation tools. Our method incorporates a cutting-edge in-context learning framework to enhance flexibility and efficiency in tasks like spatial alignment, component merging, and regional grouping. By leveraging open-world VLMs, we ensure that document edits preserve coherence and intent. To benchmark our approach, we introduce a new evaluation suite and protocol that assess both spatial and semantic accuracy, demonstrating significant advancements in structured document editing. |

|
Vaibhav Agrawal, Niharika Vadlamudi, Muhammad Waseem, Amal
Joseph, Sreenya Chitluri, Ravi Kiran Sarvadevabhatla
We present LineTR, a novel two-stage approach for precise line segmentation in diverse and challenging handwritten historical manuscripts. LineTR's first stage uses a DETR-style network and a hybrid CNN-transformer to process image patches and generate text scribbles and an energy map. A robust, dataset-agnostic post-processing step produces document-level scribbles. In the second stage, these scribbles and the text energy map are used to generate precise polygons around text lines. We introduce three new datasets of Indic and South-East Asian manuscripts and demonstrate LineTR's superior performance and effectiveness in zero-shot inference across various datasets. |
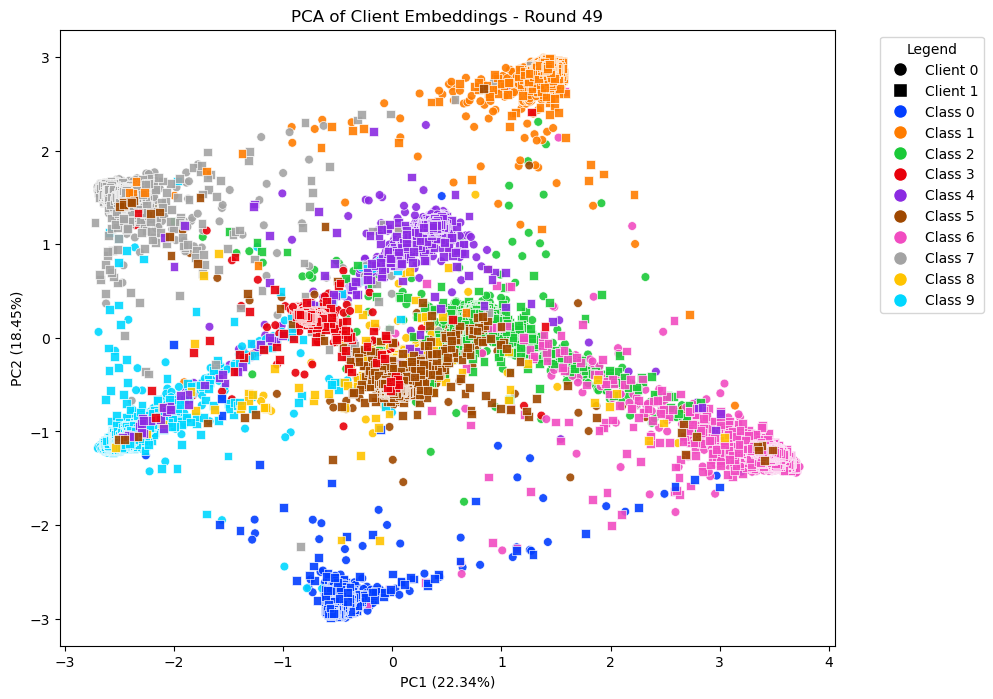
|
Explored Nearest Neighbor-Based Classification in Federated Learning with Inspiration from Semantic Drift Compensation in Class-Incremental learning to improve model robustness in highly non-IID settings. Achieved promising results in proof-of-concept visualizations. |
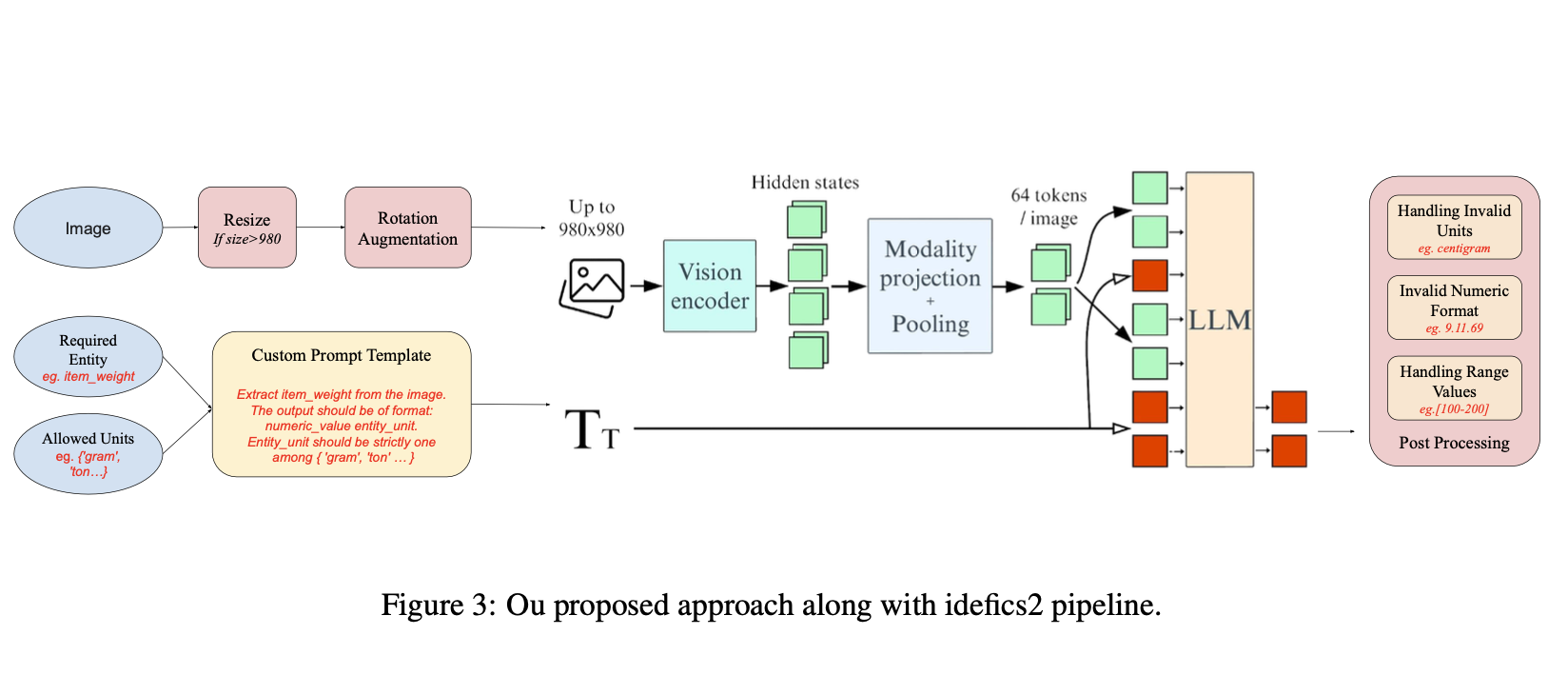
|
Utilized Vision-Language Model (VLM) with custom prompt template and an augmentation pipeline to accurately extract product details from images. Built a robust post-processing pipeline to validate extracted data's measurement units. Improved the overall F1 score by 17% |
More projects can be found on Github
|
So, you've made it till the end : ) |
Last updated: December 31, 2025